I ran /context in Claude Code and found my memory files eating 49.5k tokens before I’d typed a single word. I’d assumed those files loaded only when relevant. They were loading in full, every session. After moving them to the managed memory directory and disabling one plugin I never use, startup context dropped from 82.1k to 37.2k.
Before Link to heading
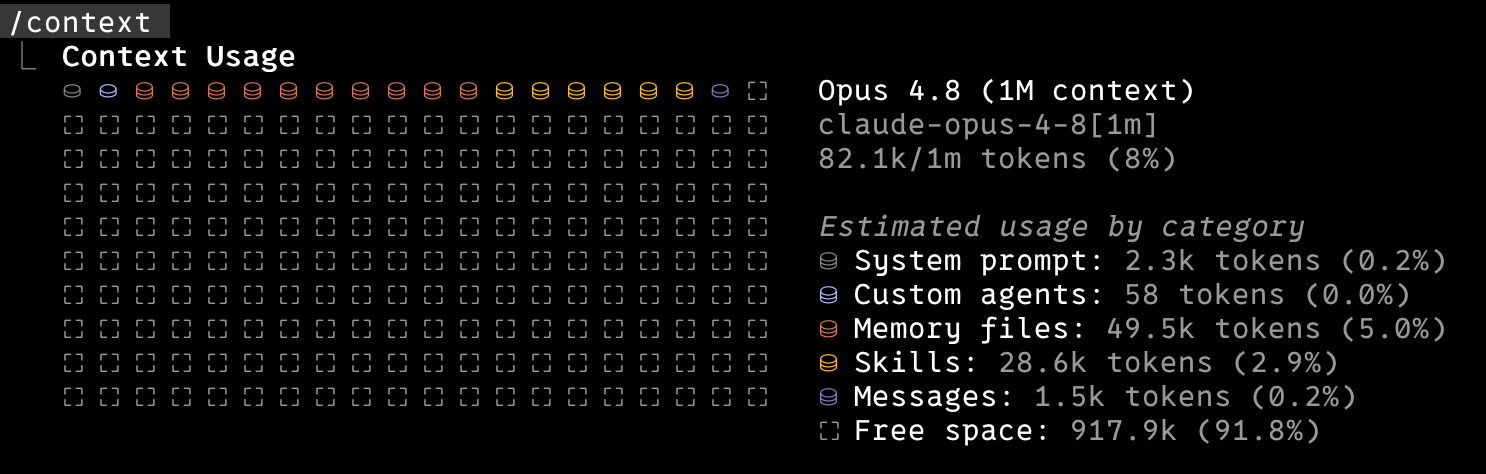
The two big line items were memory files and skills. 49.5k of that was 69 personal memory files, one fact per file: tone preferences, git habits, work conventions, the usual accumulated notes.
Where I was wrong Link to heading
I had a ~/.claude/CLAUDE.md that imported an index file, which in turn imported all 69 memories with the @ syntax:
# MEMORY.md
@~/.claude/memory/user_profile.md
@~/.claude/memory/feedback_no_em_dashes.md
... 67 more
I believed this was progressively disclosed, that each file loaded only when a task touched it. I asked Claude whether the setup was sound and got a confident “yes, correct by design” more than once. The answer changed after I checked the docs and ran ls on the directories.
The Claude Code memory docs settle it:
Imported files are expanded and loaded into context at launch alongside the CLAUDE.md that references them. Imported files can recursively import other files, with a maximum depth of four hops.
@ imports are eager and recursive. Every file in that chain loads at startup whether or not the session ever needs it. By writing that index, I turned a lazy-by-default system into an eager one.
Two memory systems Link to heading
Claude Code has a separate lazy-loading system called auto memory. It lives in ~/.claude/projects/<project-slug>/memory/. Only the index (MEMORY.md, first 200 lines or 25KB) loads at startup. The individual topic files load on demand when Claude reads them during a session.
My 69 files sat in a different directory, ~/.claude/memory/, force-loaded by the hand-written @ chain. The managed auto-memory directory was sitting empty. I was paying the eager cost while the lazy machinery went unused.
What I changed Link to heading
Move the files into the managed directory and stop importing them by hand.
mv ~/.claude/memory/*.md ~/.claude/projects/<project-slug>/memory/
Then I rebuilt MEMORY.md as a plain index, one line per memory with a short hook, rather than a list of @ imports:
- [feedback_no_em_dashes](feedback_no_em_dashes.md): Never use em-dashes in any output
- [user_communication_tone](user_communication_tone.md): Tone for messages on my behalf
The @ prefix is the difference. With it, the file is inlined at launch. Without it, the line is a pointer that the recall system surfaces when it judges the file relevant. I also removed the now-dead @MEMORY.md line from CLAUDE.md and a couple of stale references that still pointed at the old directory.
There is a trade-off. Eager import keeps a rule in context on each turn. Recall is good but not certain, so a behavioural rule can sometimes fail to surface. For the handful of rules I never want skipped, I’d keep those inline in CLAUDE.md itself. The bulk that only matters in context moved to recall.
The skills side Link to heading
Skills behave better than I feared. Only each skill’s name and description load at startup, not the body, so the catalogue is already progressively disclosed. The 28.6k was the cost of having 192 skills installed across many plugins. The single largest block came from one analytics plugin I’d never invoked, around 130 skills on its own. Disabling that plugin in settings.json was the lever:
"some-plugin@marketplace": false
Pruning is plugin-level, not per-skill. Set it to false to drop the whole block from the catalogue while keeping the cache, so re-enabling later is instant.
After Link to heading
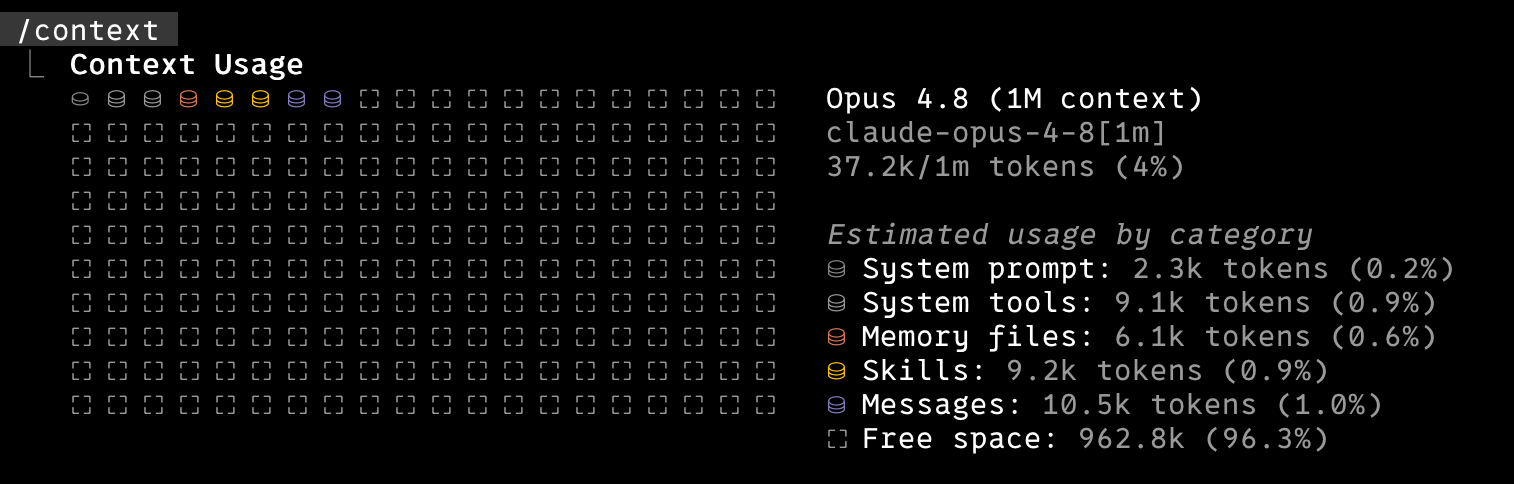
| Category | Before | After |
|---|---|---|
| Memory files | 49.5k | 6.1k |
| Skills | 28.6k | 9.2k |
| Total | 82.1k | 37.2k |
Memory files don’t hit zero, since the index plus whatever a session loads still counts. I now pay roughly for what a session touches rather than for the whole accumulated pile.
What I took from it Link to heading
I try to check /context now and then. The figure grows as I add memories and plugins, and the expensive part can be a default I didn’t set deliberately. The bit that stuck with me was simpler: I leaned on confident answers from myself and the assistant instead of checking the docs and the directory first. Listing the directory and reading the docs gave me the answer the confident replies hadn’t.
Further reading Link to heading
- Claude Code memory docs - imports, auto memory, and the loading rules
- Pruning Claude Code conversation history - a different kind of Claude Code bloat, on disk rather than in context